背景
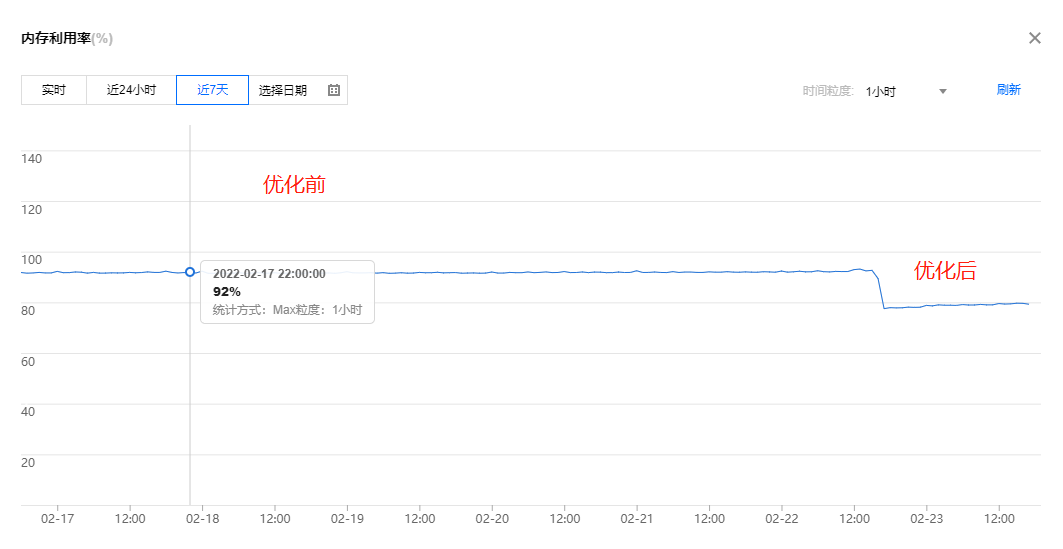
笔者在一个测试环境安装了腾讯的社区版蓝鲸系统,按照官方指引的建议,把作业平台的后端服务(Job)安装到一台8核16G内存的云服务器上。当服务安装完毕上线之后,因为在同一台主机上运行了好几个占用内存较多的Java进程,系统监控显示的内存使用率就已经在88%左右徘徊了。使用了几个月后,可能因为业务逐渐增多,内存使用率偶尔会到达90%,直到后来稳定在90%以上,触发了内存告警。
原因
发现服务器内存使用率高,第一反应都是先看看是哪些进程占用的内存多。
1
2
3
4
5
6
7
8
9
| # 查看内存使用率最高的前5个进程
# ps -aux | head -n 1 ; ps -aux | sed 1d | sort -nr -k 4 | head -n 5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
blueking 24917 1.4 9.7 7529728 1588208 ? Ssl 2021 1518:20 /usr/bin/java -server -Dfile.encoding=UTF-8 -Dspring.profiles.active=native,prod -Dspring.config.additional-location=file:///data/bkce/etc/job/application-execute.yml -Djob.log.dir=/data/bkce/logs/job -DBK_JOB_CONFIG_DIR=/data/bkce/etc/job -Xms1g -Xmx1g -jar /data/bkce/job/backend/job-execute/job-execute.jar
blueking 24846 0.7 6.5 7096600 1059108 ? Ssl 2021 823:27 /usr/bin/java -server -Dfile.encoding=UTF-8 -Dspring.profiles.active=native,prod -Dspring.config.additional-location=file:///data/bkce/etc/job/application-analysis.yml -Djob.log.dir=/data/bkce/logs/job -DBK_JOB_CONFIG_DIR=/data/bkce/etc/job -Xms1g -Xmx1g -jar /data/bkce/job/backend/job-analysis/job-analysis.jar
blueking 24841 0.9 6.3 7035020 1037368 ? Ssl 2021 1023:46 /usr/bin/java -server -Dfile.encoding=UTF-8 -Dspring.profiles.active=native,prod -Dspring.config.additional-location=file:///data/bkce/etc/job/application-manage.yml -Djob.log.dir=/data/bkce/logs/job -DBK_JOB_CONFIG_DIR=/data/bkce/etc/job -Xms1g -Xmx1g -jar /data/bkce/job/backend/job-manage/job-manage.jar
blueking 24839 0.7 5.6 6466876 913376 ? Ssl 2021 750:39 /usr/bin/java -server -Dfile.encoding=UTF-8 -Dspring.profiles.active=native,prod -Dspring.config.additional-location=file:///data/bkce/etc/job/application-backup.yml -Djob.log.dir=/data/bkce/logs/job -DBK_JOB_CONFIG_DIR=/data/bkce/etc/job -Xms512m -Xmx512m -jar /data/bkce/job/backend/job-backup/job-backup.jar
blueking 24889 0.7 4.6 6496684 755440 ? Ssl 2021 796:31 /usr/bin/java -server -Dfile.encoding=UTF-8 -Dspring.profiles.active=native,prod -Dspring.config.additional-location=file:///data/bkce/etc/job/application-crontab.yml -Djob.log.dir=/data/bkce/logs/job -DBK_JOB_CONFIG_DIR=/data/bkce/etc/job -Xms512m -Xmx512m -jar /data/bkce/job/backend/job-crontab/job-crontab.jar
|
很明显,使用内存高的都是Job的后端服务,而且都是Java进程。再进一步分析发现,这些Java进程都是在启动的时候通过Xms和Xmx参数指定了内存的分配。
根据Java的文档解释,这两个参数分别解释如下:
以内存占用排第一的job-execute.jar为例,进程的启动命令是:
1
2
| /usr/bin/java -server -Dfile.encoding=UTF-8 -Dspring.profiles.
active=native,prod -Dspring.config.additional-location=file:///data/bkce/etc/job/application-execute.yml -Djob.log.dir=/data/bkce/logs/job -DBK_JOB_CONFIG_DIR=/data/bkce/etc/job -Xms1g -Xmx1g -jar /data/bkce/job/backend/job-execute/job-execute.jar
|
可以看到,在进程初始化的时候,就分配了1G的内存空间,虽然最大值也是1G,但是当有多个类似的进程都在运行的时候,系统的内存使用率就会维持在一个较高的水平。
Java垃圾回收机制
在开始对这个Java进程进行性能优化之前,我们有必要先来简单了解一下Java的性能回收机制。
垃圾回收指的就是Java程序自动内存管理的过程。当Java代码经过编译,并运行在JVM(Java Virtual Machine)上的时候,会把创建的对象存放在内存空间中一个叫做heap的地方。随着程序的运行,有一部分弃用的对象需要被回收,让内存空间得以释放,这就是垃圾回收。
垃圾回收原理
Java的垃圾回收是自动进行的,程序员不需要显式地在代码中标记要删除的对象。当一个Java程序启动的时候,同时也就创建了一个JVM实例,JVM会在自身规范的框架内自动地进行垃圾回收。而JVM也分很多种,本文以Oracle的Hotspot JVM为例子进行讨论。
根据不同的场景,我们可能会采取不同的垃圾回收方法,但在众多垃圾回收方法里面,都遵从一个基本的流程:
未引用的对象会被识别,并标记为即将被回收。
删除被标记的对象
根据不同的选项,对象在内存中被删除后,垃圾回收器可能会对释放出来的内存空间进行碎片整理,使进程在后续调用和分配内存空间的时候更加顺畅。内存空间的碎片整理又能涉及到很多讨论,这里暂不赘述。
Generational Hypothesis
在对内存空间更替的研究中,研究人员发现在大多数时候,内存中的对象都会很快变得无用,等待被删除。

heap的空间划分
又为了在回收内存空间的同时减少对进程的影响,在JVM的设计理念中,对把内存空间分成了不同的区间。
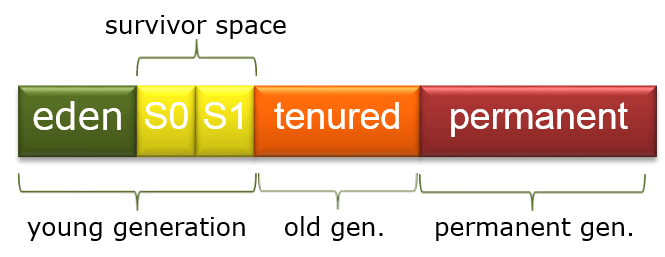
Young Generation:新创建的对象会存放在Eden中,当Eden中剩余的空间不足以容纳最新的对象时,就会清理无用的对象,并把仍在使用中的对象存放到其中一个survivor space中。这个过程也被称之为minor garbage collection event。两个survivor space必然有一个处于空置状态,每一次发生minor garbage collection event就会把有内容的survivor space中的对象以及在Eden中幸存的对象转移到空置的survivor space中,同时会统计每一个幸存对象的幸存次数(年龄)。
Old Generation:在Young Generation区间存活得足够久的对象,最终会升级为tenured(可以理解为终身任职),就被移动到Old Generation空间中。当在Old Generation的对象被回收时,就称为一次major garbage collection event。
Permanent Generation:代码中定义的众多类以及方法的元数据就会存放在这个区间。
在minor和major两种garbage collection event之外,还有full garbage collection event,整一个heap都会被清理。
进一步分析
回到对这个内存告警的处理上。既然已经确定了是内存分配参数决定了进程的内存使用,接下来应该思考的是,能不能把这个值调整到一个合适的水平。既可以节省内存的占用,又不至于明显地影响进程的运行。
假设我对这个进程降低内存空间分配,可以预见的是,Java进程可能会增加一定的开销用于更频繁的垃圾回收。但我们也可以在上面的ps输出看到,这些Java进程都只使用了极少的CPU时间。那我们可以猜测,进程内部并没有强运算的需求,又或者,在当前的运行状态下,本身也没有很频繁的垃圾回收场景。
另外发现,进程启动的时候并没有指定垃圾回收方式,通过下面的输出我们可以得知,默认情况下,使用的是并行(Parallel)方式:
1
2
3
4
5
| # java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=788684800 -XX:MaxHeapSize=12618956800 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
|
但我们通过进程的CPU使用率可以猜测,垃圾回收并没有产生很明显的开销,所以这个不是重点。
再进一步查看PID 24917的JVM垃圾回收状况,得到输出如下:
1
2
3
4
5
6
7
8
9
10
11
| # jstat -gc 24917
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
64512.0 62464.0 24318.5 0.0 222208.0 21500.1 699392.0 635168.7 123176.0 113065.4 14632.0 12970.9 7018 196.774 13 3.711 200.485
# jstat -gccapacity 24917
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
349184.0 349184.0 349184.0 64512.0 62464.0 222208.0 699392.0 699392.0 699392.0 699392.0 0.0 1157120.0 123176.0 0.0 1048576.0 14632.0 7018 13
# jstat -gcutil 24917
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
37.70 0.00 10.29 90.82 91.79 88.65 7018 196.774 13 3.711 200.485
|
提取一部分关键信息:
把Heap中的各个区间面积可视化显示如图: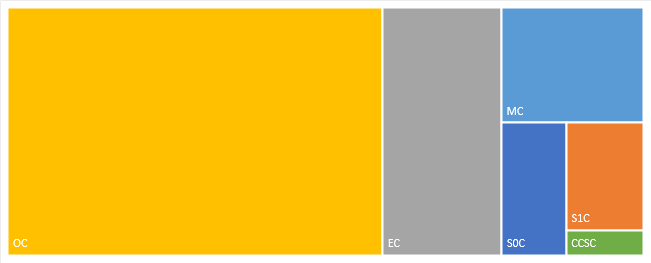
可以明显看到,Old Generation的空间最大。
FGC: Number of full GC events. ——进程存活期间(两个多月)只是产生了13次。
FGCT: Full garbage collection time. ——一共花了3.711秒。
YGC:Number of young generation GC Events. ——也即是上面提到的Minor GC,发生了7018次。
YGCT:Young generation garbage collection time. ——196.774秒,平均每一次Minor GC使用了0.02秒。
E: Eden space utilization as a percentage of the space’s current capacity. ——Eden中只是用了10%左右。
O: Old space utilization as a percentage of the space’s current capacity. ——Old Generation的空间占了90.82%。
可能是因为这是在测试环境的应用,业务量几乎是零,再加上充足的内存空间,大多数对象都已经在里面安居乐业甚至落地生根了。而且,考虑到服务器本身还有极大的CPU性能可以调用,因内存空间减少而导致的性能开销增加是可以忍受的。
那我们就不需要客气了,可以大刀阔斧地减少对这个进程的内存分配。
具体方案
有了初步方案之后,我们知道,只需要修改进程启动时候的Xms和Xmx参数,再重启这个进程就可以了。
根据蓝鲸系统的操作文档,这些进程都是通过systemctl启动的。
继续以这个job-execute服务为例子,在.service文件中,指定了通过文件/etc/sysconfig/bk-job-execute获取环境变量,在环境变量中通过$JAVA_OPTS配置了内存参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| # cat /usr/lib/systemd/system/bk-job-execute.service
[Unit]
Description=bk-job-execute.service
After=network-online.target
PartOf=bk-job.target
[Service]
User=blueking
EnvironmentFile=-/etc/sysconfig/bk-job-execute
WorkingDirectory=/data/bkce/job/backend/job-execute
ExecStartPre=/bin/bash -c "until host job-config.service.consul; do sleep 1; done"
ExecStartPost=/bin/bash -c 'until [ $(curl -s -o /dev/null -w "%{http_code}" http://localhost:8500/v1/agent/health/service/name/job-execute?pretty) == 200 ]; do echo "waiting job-execute online";sleep 1; done'
ExecStart=/usr/bin/java -server -Dfile.encoding=UTF-8 $SPRING_PROFILE $CONFIG_FILE $LOG_DIR $CONFIG_DIR $JAVA_OPTS -jar $BINARY
StandardOutput=journal
StandardError=journal
SuccessExitStatus=143
LimitNOFILE=204800
LimitCORE=infinity
TimeoutStopSec=60
TimeoutStartSec=180
Restart=always
RestartSec=3s
[Install]
WantedBy=bk-job.target
# cat /etc/sysconfig/bk-job-execute
SPRING_PROFILE="-Dspring.profiles.active=native,prod"
CONFIG_FILE="-Dspring.config.additional-location=file:///data/bkce/etc/job/application-execute.yml"
CONFIG_DIR="-DBK_JOB_CONFIG_DIR=/data/bkce/etc/job"
LOG_DIR="-Djob.log.dir=/data/bkce/logs/job"
BINARY=/data/bkce/job/backend/job-execute/job-execute.jar
JAVA_OPTS="-Xms1g -Xmx1g"
|
所以,我们只需要修改/etc/sysconfig/bk-job-execute里面的内容,再重启bk-job-execute服务就可以了。在这里,我们把最后一行修改为:
1
| JAVA_OPTS="-Xms512m -Xmx512m"
|
结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 运行数天后, 观察到占用的内存使用率从9.7%下降到5.2%, CPU使用率依旧很低,并且运行稳定
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
blueking 24858 1.5 5.2 6983056 846948 ? Ssl Feb22 26:06 /usr/bin/java -server -Dfile.encoding=UTF-8 -Dspring.profiles.active=native,prod -Dspring.config.additional-location=file:///data/bkce/etc/job/application-execute.yml -Djob.log.dir=/data/bkce/logs/job -DBK_JOB_CONFIG_DIR=/data/bkce/etc/job -Xms512m -Xmx512m -jar /data/bkce/job/backend/job-execute/job-execute.jar
# Heap里面Eden的占比比之前更合理了
# jstat -gcutil 24858
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
78.81 0.00 49.39 58.22 93.55 91.14 276 4.525 4 0.577 5.103
# 也没有很频繁的垃圾回收
# jstat -gc 24858
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
20992.0 20480.0 16544.7 0.0 133120.0 66854.0 349696.0 203587.1 119080.0 111400.0 14120.0 12868.7 276 4.525 4 0.577 5.103
|
经过类似的分析后,对其他不合理分配内存空间的Java服务也相应进行了调整,最后系统的内存使用率从92%下降到了79%。
总结
在完成这个参数优化之后,笔者有猜测过,为什么蓝鲸的团队会在安装脚本上制定出这样看起来是虚高的运行参数。也许是基于验收标准的需要,也许是为了让服务更稳定地运行,也许只是单纯地继承了开发环境上面的运行参数。
诚然,站在我一个运维的角度,比起上线后去思考如何调参,更理想的状况是让开发者在开发阶段就多多关注jvm的运行形况不断优化代码逻辑,让程序可以多快好省地运行。但既然程序已经交付并且上线,根据线上业务的实际情况因地制宜地对服务进行调优也是运维的分内事。只能说,遇到问题就积极应对,这才是正路。
而说回这个事例,回想起大学时候的专业课很印象深刻的一点,就是老师跟我们总结到:“计算机科学里面的很多方法论,本质上就是用时间换空间,或者是是用空间换时间。”这次是CPU低内存高的情况,要是反过来,我们就要思考加大内存空间的分配了。能调参解决就调参,不行就加硬件,这也算是运维日常的一部分。
以上都只是通过一个简单的运维日常作为引子,讨论一下关于JVM性能优化的思路。真正操作起来,也只是敲几下键盘的功夫,涉及到的原理也不高深,但可以通过这里给一些萌新一些扩展思考:
- JVM的垃圾回收机制原理
- 如何实时监控一个java进程的垃圾回收情况
- JVM的性能参数还有哪些,都会影响到什么地方
- 操作系统的内存使用率是如何计算的
- ……
(最近太忙了,水一篇)