容器工作原理简述
前言
笔者最初接触容器技术的时候,心中是充满疑问的。
“容器是一个进程吗?”
“和虚拟机有什么区别?”
“使用容器后,服务器内部到底发生了什么?”
……
后来,经过了较长的一段时间的学习,从实践到理论知识,才慢慢地摸索和总结出容器的工作原理。
跟往常的行文方式不同,这次会使用很多短句和换行,力求简明扼要地把概念说完。
毕竟,如果想要详细的话,我为什么不去看官方文档呢? :-)
另外需要强调一点,本文讨论的是关于容器技术的通用解决方案,旨在简单介绍容器的设计思路和实现方式,可能会和现有的一些具体的容器方案有出入。
为什么使用容器
大家不难看出,最近几年,尤其是2018年以来,网上就有了很多关于容器技术的讨论,甚至会有点“饭圈”的感觉,到处都在推崇容器以及微服务的理念,仿佛容器可以解决一切的问题。
- 编译环境调试难,用容器
代码开发完成后,在线上服务器的编译环境中发现一些组件的版本不对,又得重新去定位问题安装依赖。而一个项目中因为敏捷开发或者是管理不成熟等问题,往往又会需要有很多不同的编译环境,带来巨大的管理成本。
后来,人们在容器里面完成代码编译,甚至有很多CI工具都开始支持使用容器进行代码编译。
- 操作系统版本要并存,用容器
就算服务器使用的是最新版本的操作系统,也不影响我们在一个容器里面运行一个旧版本的。
- 想要快速部署,用容器
开发环境使用Python3.6,上线的时候发现线上服务器使用的是Python3.5,怎么办? 还是用容器,把服务封装在一个Python3.6环境的容器内直接上线。
- 容器YYDS!
容器的理念就是:要啥有啥
我们看docker的logo,就是一头鲸鱼和几个集装箱,docker提供的就是一种标准化的理念。
而回到容器本身,就是容器里面都包含了程序运行所需的所有依赖。
容器镜像就是一个文件系统的压缩包,比如说,一个典型的用Rails开发的应用,封装成容器之后,里面会包含:
源代码
libc和其他系统lib
Ubuntu操作系统
Ruby interpreter
Ruby gems
都知道我们可以使用docker build去构建一个容器镜像,那容器镜像又是怎么build出来的?
先确定一个操作系统
安装必要的程序和依赖
按需配置
打包
那如果要运行容器镜像呢?
下载镜像
解压缩到指定路径
假装上面那个指定路径就是一个完整的文件系统,运行里面的程序
手动模拟一个小容器
在启动容器之前,要先安装cgroup工具,以Ubuntu为例:
1 | sudo apt install cgroup-tools |
下面的小脚本可以在容器里面运行一个fish shell,需要以root权限去运行:
1 | #!/bin/bash |
容器 = 进程
一个容器就是一个或组Linux进程(如果你在MacOS上,你的容器是运行在Linux虚拟机里面)。
如下图,左边是容器里面的shell,右边是容器外的shell。我在容器里面运行top命令,在容器外使用ps命令也可以查到到容器里面的top进程。
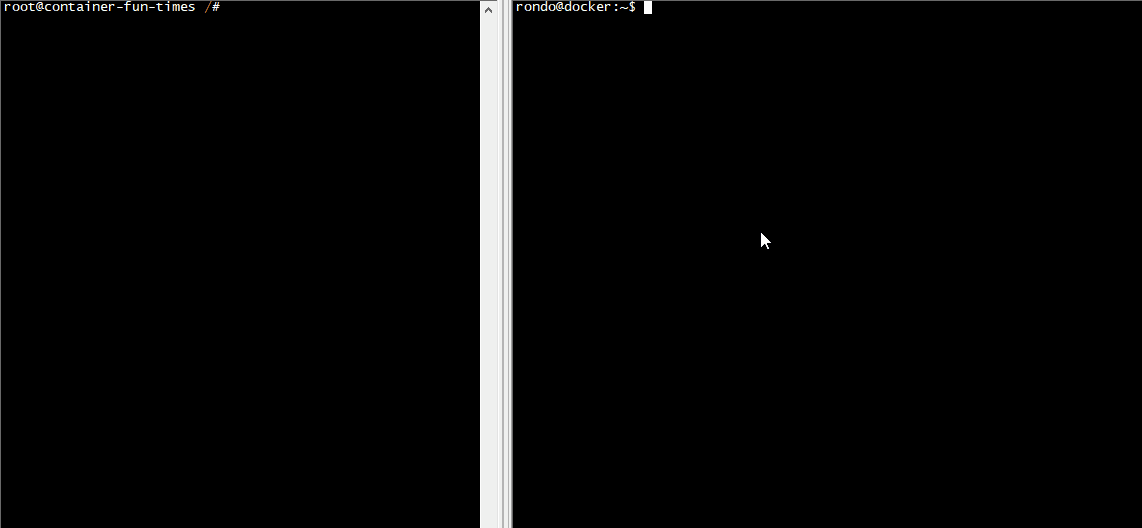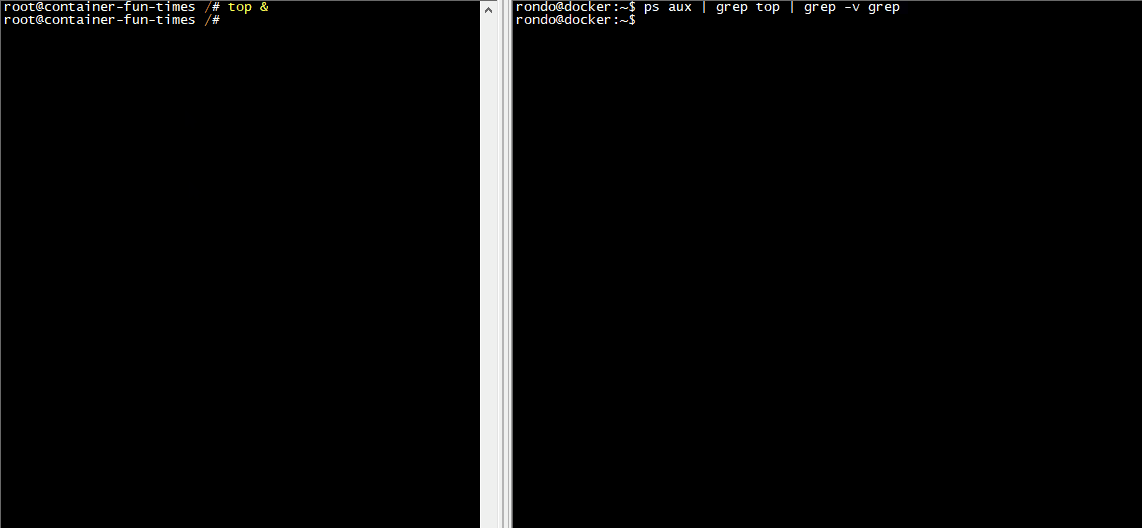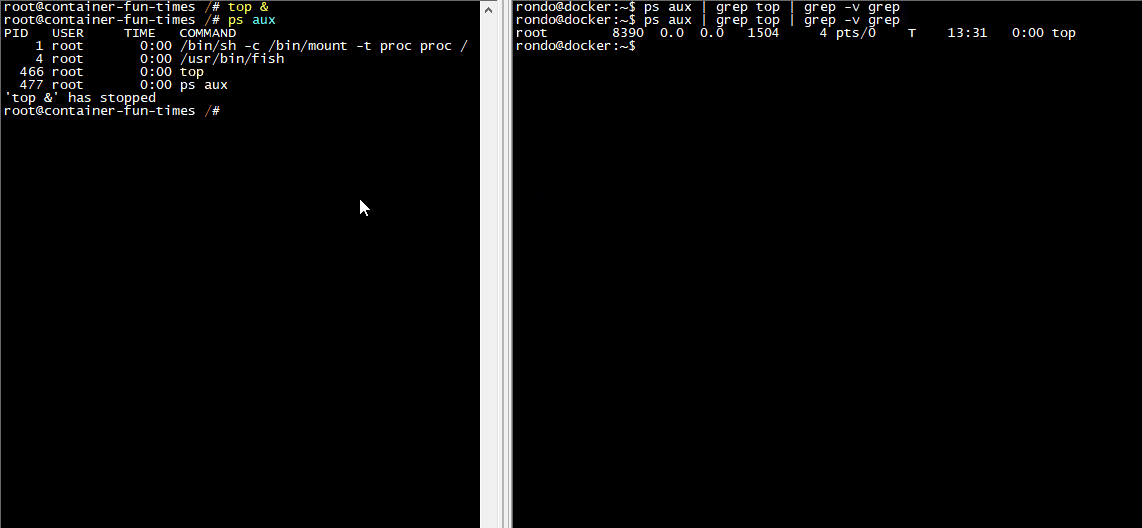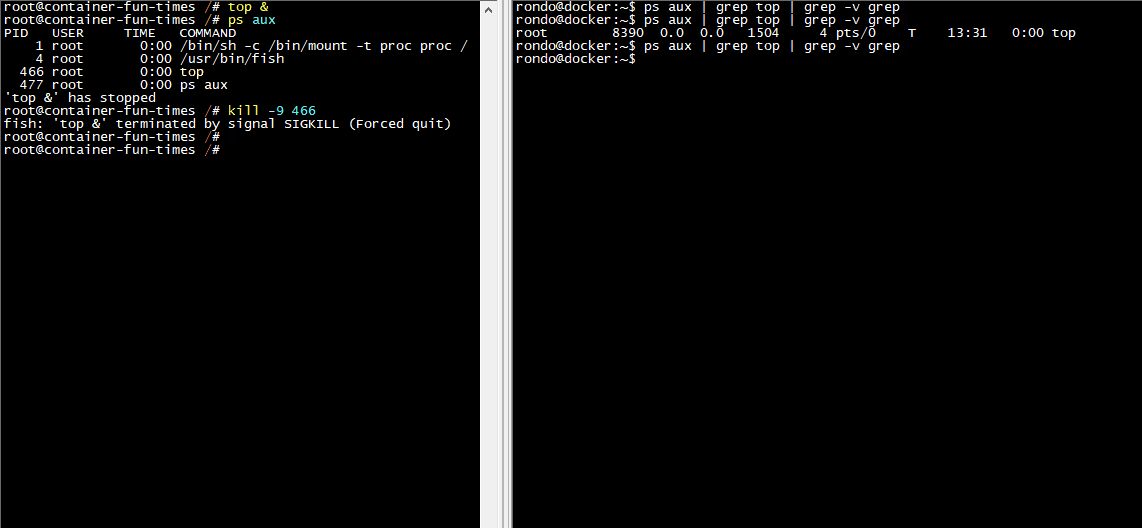
在容器里面的进程和容器外面的并无两样,但是会受到一些由Linux内核所规范的限制,比如说:不同的PID namespace、不同的根目录、内存限制、capability限制、部分系统调用被屏蔽等,后面我们会讲到这些内容。
容器内核feature
容器并没有一个很明确的定义,但以Docker为例,会用到下面的这些feature:
pivot_root
cgroup
namespace
capability
seccomp-bpf
overlay文件系统
pivot_root
前面提到,容器镜像里面是一个打包好的文件系统,当收到一个容器镜像的时候,我们会通过chroot的原理去使用这个压缩包。
举例说,在执行chroot /fake/root后,当我运行/usr/bin/redis的时候,我实际上是在运行/fake/root/usr/bin/redis。
但如果你直接在自己的环境里面执行chroot,大概率会返回一个报错说chroot: failed to run command ‘/bin/bash’: No such file or directory。
也就是说,你的新root最起码得有一个shell环境才行,后面我们说到容器镜像的时候会进一步说明这个问题。
我们可以用chroot去理解pivot_root,但其实两者实现的原理不一样。最大的区别就是,在chroot环境下运行的进程,还是有机会访问到原来的根目录(google搜索’break out chroot jail’),而使用pivot_root后,旧的文件系统就会被卸载(umount)掉了。
因此,pivot_root比chroot安全。
文件系统的layer(s)
我们往往会在一个主机上运行多个容器,而不同的容器镜像里面很有可能会有重复的文件,比如说,Rails和Django可能都会运行在Ubuntu 18.04上。
在容器技术里面,我们会对文件系统分层,相同的文件会被复用,以节省磁盘空间。在上面提到的这个例子中,Rails和Django两个不同的应用,他们都使用一个相同的Ubuntu 18.04底层文件系统。
每一层文件系统就是一个目录,并且会带有一个ID,一般是通过sha256生成的哈希。
如果多个同名的文件同时存在在多层里面,我们只会看到位于上层的文件。
在默认情况下,所有对文件系统的写操作都会发生在一个临时层,当容器退出后,临时层里面的写操作都会丢失。所以,当我们在容器里面要保存写入操作,比如说日志,都需要在容器里面额外挂载一个容器外的文件系统。
overlay文件系统
在Linux的mount命令的-t选项里面,有一个“overlay”选项,可以把多个不同layer的文件系统合并成一个。mount -t overlay命令有四个参数:
lowerdir:只读层
upperdir:在容器运行过程中,对文件的创建、修改、删除等修改操作都会记录在这个layer中,当容器运行结束,里面的内容也会被删除
workdir:用于容器内部使用的空路径
target:合并后的文件系统的挂载点
下面是一个例子:
1 | root@docker:/# ls /merged/ |
容器镜像仓库(registry)
我们可以通过镜像仓库来分享不同的容器镜像,每个镜像都会有个ID(例如Ubuntu)和标签(例如18.04或latest)。当我们从镜像仓库下载镜像的时候,会先对比本地已有的layer,接着再下载我们所缺失的layer。
镜像仓库分成公共和私有两种,在公共镜像仓库(如dockerhub)里面能找到很多开源社区里面的官方镜像(例如redis或者flask等)。
注意不要运行来历不明的容器镜像。
更要注意不要把公司的业务镜像在公共仓库中共享。(不会真有人这样做吧?)
cgroup
当一台服务器只有16GB的内存空间,而服务器内的多个进程请求的内存资源有可能会超过16GB,从而导致OOM引起程序崩溃。
针对这种情况,我们可以使用cgroup去限制进程的CPU和内存使用额度。
cgroup就是一组进程,在同一个容器内的进程,就是在同一个cgroup中。
cgroup中的所有进程共用同一套cpu/内存额度。
当请求的内存资源超过cgroup的最大额度时,进程就会因为OOM被终止。
cgroup也会通过CPU额度限制进程的运行速度。
cgroup的详情可以在/sys/fs/cgroup中查看
namespace
前面我们看到,容器就是一组特殊的进程,我们在容器外面也可以看到容器里面的进程,但是在容器内部只能看到容器里面的进程,这背后就是namespace在起作用。
所有进程会有7个namespace:
1 | # lsns -p 7707 |
在默认情况下,都会使用“host”这个namespace。所有不在容器内的进程,就是在使用“host”这个namespace下。
各个不同的进程,可以对各个namespace进行组合,例如说,可能会有一个进程在使用host network namespace和自己的mount namespace。
怎样创建namespace
默认情况下,子进程会自动继承父进程的namespace,但你也可以为进程指定不同的namespace。
常用的相关命令有:
unshare:使用指定的namespace去运行一个进程lsns:查看进程的namespacensenter:在一个已有的namespace下运行命令
所有的namespace都会详细的man page:
1 | # man network_namespaces |
PID namespace
同一个进程在不同的namespace下,会使用不同的PID。比如说,一个容器里面的有一个pid为1234的进程,这个进程在容器外查看的时候,pid是23511。
PID namespace以树形结构组织,host pid namespace下面可能会有多个child pid namespace。在parent pid namespace下可以查看child pid namespace下的所有进程。
每个pid namespace都有一个pid为1的进程,pid 1结束或者被kill后,在同一个命名空间下的所有进程都会结束。
user namespace
user namespace是一个安全相关的功能,但不是所有的容器都会使用到它。
在进程的user namespace里面,UID会和host UID映射,记录在/proc/self/uid_map中。
没能成功映射的UID,就会显示成nobody,举例如下:
1 | # 创建一个新的user namespace |
如果想要确认两个进程的user namespace是否一样,也很容易,使用命令ls /proc/PID/ns就知道了。
network namespace
network namespace一般会有两个接口(也可能会更多),一个是loopback接口,127.0.0.1/8,用于namespace内部的连接,另一个用于外部连接。
当一个服务配置了listen 0.0.0.0:8080后,意味着要监听自身network namespace下的所有网络接口。
与此同时,每一个network namespace下面都有一个127.0.0.1地址,前面说过了,只用于namespace内部连接。
服务器的物理网卡位于host network namespace。
其他的namespace通过桥接的方式和host namespace实现连接。
容器的IP地址
容器往往都会有自己的IP地址,也很符合大家的直觉,容器使用的都是内网IP地址,因为容器都不会直接连接到互联网上。
为了让IP包都能正确地找到容器,我们需要给容器们提供网络路由服务,一般是由容器所在的服务器提供。
关于容器的网络规划和路由控制,不同的云厂商都有不同的方案,甚至不同的容器技术或者不同的容器编排工具都会不一样。比如说,在K8s原生容器集群中,是每个pod有独立的IP地址,POD之间的容器,或者是POD内的容器之间,都会有不一样的访问方式,这里就不细说了。
capability
我们一般会习惯性地以为,用root用户登录服务器之后就可以为所欲为:修改所有的文件、随便修改网络配置、监视各个进程的内存等等。但其实真正赋予这些敏感权限的并不是root这个用户,而是叫做capability的feature。
capability以分组的方式拆分了root用户的各种权限,以便我们基于场景以更小的粒度对不同的进程进行赋权。
比如说,想要修改路由表,需要CAP_NET_ADMIN,想要使用chown命令修改文件的归属,需要CAP_CHOWN……
使用命令man capabilities可以查看完整的man page。
在默认情况下,容器只有非常有限的权限。
我们可以使用命令getpcaps PID查看进程拥有什么capability。
也可以使用getcap或者setcap命令查看可执行文件所拥有的的capability。
seccomp-BPF
所有程序都需要使用系统调用(system call),哪怕只是简单地读取一个文件的内容。
有一些很敏感的系统调用,可能会被别有用心的人利用,例如:reboot、request_key、process_vm_readv等等。
seccomp的全称是SECure COMPuting with filters,得益于这个功能,来自于各个程序的系统调用都会先经过一个过滤器判断是否允许操作。
以Docker为例,在默认情况下,对容器屏蔽了大多数被认为是不必要的系统调用,从而增加了系统的安全性。
联系上面提到的capability,一般我们在容器技术的实践中都会同时使用capability和seccomp。
可能会有人问了,BPF又是什么意思。意思是:这个filter使用的是Berkeley Packet Filter。
常用的容器配置模式
一般来说,当我们使用容器的时候,下面的6中配置场景是必不可少的:
端口映射,比如说,把容器的80端口映射到服务器的其他随机端口
挂载文件,比如说把日志输出路径挂载到某个磁盘下
设置capability
设置seccomp-BPF
设置容器的CPU/内存使用额度
规范network namespace,以实现网络隔离或者穿透
总结
笔者最初接触容器结束的时候,一直都没有搞明白和虚拟机的区别,甚至就直接把容器看成是一个轻量化的虚拟机去用。直到在工作上对一个旧项目完成了基于K8s的容器改造后,对容器的理解仍然止步于怎么写dockerfile和配置yaml。
就是很典型的那句话:“能跑就行。”(笑)
再到后来经历了一些疑难杂症和故障后,才终于重视起理论,细心研究了一番。
现在,如果让我给别人解释容器技术,我大概率是先抛出一个问题:“我在一个服务器上运行了多个业务进程,要怎样才能避免他们互相影响?”
结合上文里面提过的关键词,我们可以侃侃而谈:“也不是很难啦,通过cgroup限制各个进程的性能,使用pivot_root和overlay文件系统隔离文件,用capability功能限制进程和用户的权限,再用namespace把进程信息和网络互相隔离,最后用seccomp屏蔽一些敏感的系统调用,就齐活啦!”
而当你做到这些事情的时候,你已经在使用容器技术了。
所以,就笔者看来,容器技术首先解决的,是进程隔离这个场景,这也是容器技术最初的理念。到后面的部署标准化、高可用、快速部署、提高资源使用率这些功能,都是随着docker或者K8s这些标准应用而诞生的。而很多人,也包括笔者自己,都本末倒置了。
谨以此文追忆一下当初那个不求甚解的自己。
扩展阅读
上面提到的各个关键词,都可以去google一下,大有裨益。
;-)